

오늘은 주석을 다뤄본다. 클린 코드 내용을 정리하고, 이를 바탕으로 내 프로젝트를 리팩토링해보겠다.
🧭 목차
- 주석은 나쁜 코드를 보완하지 못한다
- 코드로 의도를 표현하라
- 좋은 주석 vs 나쁜 주석
- 반드시 피해야 할 주석 유형
- 마무리 체크리스트
❌ 1. 주석은 나쁜 코드를 보완하지 못한다
- 주석은 종종 지저분한 코드를 해명하려는 변명일 뿐이다.
- 코드 자체를 더 명확하게 리팩터링하는 것이 우선이다.
Bad
// 직원에게 복지 혜택을 받을 자격이 있는지 검사한다
if ((employee.flags & HOURLY_FLAG) && (employee.age > 65))Good
if (employee.isEligibleForFullBenefits())✅ 2. 코드로 의도를 표현하라
- 변수명, 함수명, 모듈구조로 충분히 의도를 드러낼 수 있다면 주석은 필요 없다.
- “이 코드가 무엇을 하는지”보다 “왜 하는지”가 중요한 경우에만 주석을 남겨야한다.
🌟 3. 좋은 주석의 예
| 법적인 주석 | 저작권, 라이선스 표기 | // Copyright (C) 2025 by MyCompany |
| 정보 제공 | 형식, 규칙 설명 | // yyyy-MM-dd HH:mm:ss 형식입니다 |
| 의도 설명 | 비정상적 방식 설명 | // 경쟁 조건을 유도하기 위해 스레드를 대량 생성합니다 |
| 결과 경고 | 위험 요소 알림 | // 파일 크기가 너무 크면 OOM 발생 가능 |
| TODO | 향후 작업 알림 | // TODO: 이 메서드는 이후 제거 예정 |
| 중요성 강조 | 꼭 필요한 로직 설명 | // trim이 없으면 공백 때문에 파싱 실패 |
| 공개 API용 Javadoc | 외부 사용자를 위한 설명 | @apiNote 최대 1000개까지 검색 가능 |
⚠️ 4. 나쁜 주석 유형 (절대 피할 것)
❌ 주절거리는 주석
- 자기 혼잣말이나 의미 없는 설명
// 속성 파일이 없다면 기본값을 모두 읽었다는 의미
// (이건 읽는 사람이 유추할 수 있다!!!)❌ 코드 반복 주석
- 코드와 동일한 설명은 불필요하다.
// 닫혔는지 확인
if (closed)❌ 오해 유발 주석
- 동작과 다르거나 일부만 설명하면 혼란을 야기한다.
❌ 의무적으로 다는 Javadoc
- 자명한 변수/함수에 일일이 주석 다는 것은 노이즈입니다.
/**
* @param title CD 제목
* @param author CD 저자
*/
// → 코드만으로 충분히 전달됨❌ 이력 관리 주석,주석 처리한 코드
- Git이 이미 하고 있는 일이다.
// 2021-11-01: 기능 추가 by Rick✅ 5. 클린 주석을 위한 체크리스트
| 이 주석이 없어도 코드를 이해할 수 있는가? | ❓ |
| 함수/변수명으로 대체 가능하지 않은가? | ❓ |
| 주석 내용이 코드 변경에도 여전히 유효할까? | ❓ |
| 이건 과거 코드 설명이나 잡담은 아닌가? | ❓ |
| 공개 API 문서라면 Javadoc은 유지해야 합니다 | ✅ |
✍️ 좋은 주석이란
“좋은 코드에 주석은 필요 없다. 그래도 남긴다면, 정말로 필요한 한 줄만 남기자.”
🧹 클린코드 리팩토링: 주석이 아니라 함수로 말하기
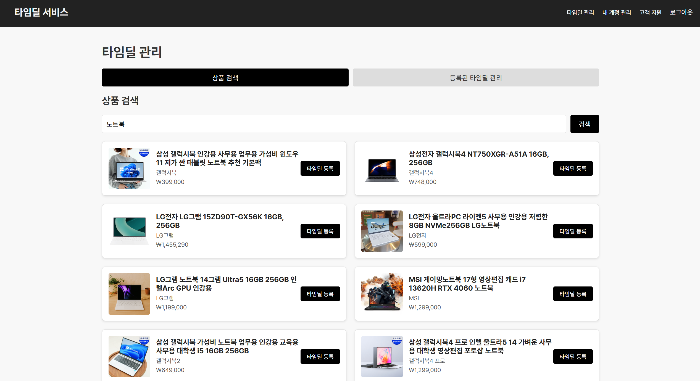
오늘의 총체적 난국 코드이다. 이 코드는 네이버 쇼핑API를 통해 상품 검색 기능을 구현하는 내용을 담고있다.
이제 클린코드 주석의 원칙에 맞게 리팩토링 해보려 한다.
(참고로 변명을 해보자면...일부러 기능만 막 구현하고 리팩토링하려고 더 더럽게만든것도 있다)
✅ before – 주석 없이 읽히지 않는 최악의 코드
/**
* Product 조회 및 타임딜 등록
* */
@RestController
@RequestMapping("/api/products")
public class ProductSearchController {
@Value("${naver.client-id}")
private String clientId;
@Value("${naver.client-secret}")
private String clientSecret;
@Value("${naver.api-url}")
private String NAVER_API_URL;
/**
* 상품을 검색하는 함수. (Naver Shopping API 사용)
* 주어진 검색 조건에 맞는 상품들을 데이터베이스에서 조회하여 반환.
*
* @param searchQuery 검색할 상품의 키워드나 조건. 예를 들어, 상품명, 브랜드, 카테고리 등.
* @param category 상품 카테고리. 선택적으로 필터링 가.
* @param priceRange 가격 범위. 선택적으로 필터링할 가능.
* @param pageNum 검색 결과 페이지 번호. 기본값은 1로 설정.
* @param pageSize 한 페이지에 표시될 상품의 수. 기본값은 10으로 설정. (최대 100페이지)
*
* @return 검색 조건에 맞는 상품들의 리스트. 조건에 맞는 상품이 없으면 빈 리스트를 반환.
*/
@GetMapping("")
public ResponseEntity<BaseResponse<Map<String, Object>>> searchProducts(
@RequestParam String query,
@RequestParam(defaultValue = "1") int page) {
int display = 10; // 페이지당 항목 수
// 총 페이지 수 계산
String apiUrl = NAVER_API_URL + "?query=" + query + "&display=" + display + "&start=1"; // 임시로 시작 페이지는 1로 설정
// HTTP 헤더 설정
HttpHeaders headers = new HttpHeaders();
headers.set("X-Naver-Client-Id", clientId);
headers.set("X-Naver-Client-Secret", clientSecret);
HttpEntity<String> entity = new HttpEntity<>(headers);
// API 호출
RestTemplate restTemplate = new RestTemplate();
ResponseEntity<Map> response = restTemplate.exchange(apiUrl, HttpMethod.GET, entity, Map.class);
// 응답 데이터 처리
Map<String, Object> result = new HashMap<>();
Map<String, Object> body = response.getBody();
assert body != null;
// 전체 검색 결과 수 확인
int totalResults = (int) body.getOrDefault("total", 0);
// totalResults 10으로 나누어 총 페이지 수 계산
int totalPages = (int) Math.ceil((double) totalResults / display);
// 페이지 번호가 총 페이지 수보다 크면 마지막 페이지로 조정
if (page > totalPages) {
page = totalPages;
}
// 페이지 번호에 맞게 시작 인덱스를 계산
int start = (page - 1) * display + 1;
if (start > 1000) { // start 값이 1000을 초과하지 않도록 제한 (API 자체 제한)
start = 1000;
}
// API URL (start 값 수정)
apiUrl = NAVER_API_URL + "?query=" + query + "&display=" + display + "&start=" + start;
// API 호출
response = restTemplate.exchange(apiUrl, HttpMethod.GET, entity, Map.class);
body = response.getBody();
assert body != null;
result.put("items", body.get("items"));
result.put("currentPage", page);
result.put("total", totalResults);
result.put("display", display);
result.put("totalPages", totalPages);
return ResponseEntity.ok(new BaseResponse<>(BaseResponseStatus.SUCCESS, result));
}
}
먼저 가독성도 안좋고, 주석을 따라가야 흐름이 이해되는 구조이다. 또한 클린 코드 함수 원칙(최소기능 원칙)에도 어긋난다.
문제점
- 기능이 한 메서드에 다 몰려 있다.
- 주석 없이는 무슨 일이 일어나는지 파악하기 어렵다.
- 변수명, 메서드명이 의도를 표현하지 못한다.
- 주석이 “설명서”가 아니라 “변명서”가 되어버린 사례다ㅎ
✅ after – 주석 없이도 읽히는 코드
/**
* 네이버 쇼핑 API 기반 상품 검색 컨트롤러
*/
@RestController
@RequestMapping("/api/products")
@RequiredArgsConstructor
public class ProductSearchController {
private static final int ITEMS_PER_PAGE = 10;
private static final int MAX_SEARCHABLE_ITEMS = 1000;
@Value("${naver.client-id}")
private String clientId;
@Value("${naver.client-secret}")
private String clientSecret;
@Value("${naver.api-url}")
private String naverApiUrl;
private final RestTemplate restTemplate;
/**
* 네이버 쇼핑 상품 검색 API
*
* @apiNote 네이버 API 정책상 최대 1000개 항목까지만 조회 가능
*/
@GetMapping
public ResponseEntity<BaseResponse<Map<String, Object>>> searchProducts(
@RequestParam String query,
@RequestParam(defaultValue = "1") int page) {
Map<String, Object> searchResult = executeNaverApiSearch(query, page);
return ResponseEntity.ok(new BaseResponse<>(BaseResponseStatus.SUCCESS, searchResult));
}
private Map<String, Object> executeNaverApiSearch(String query, int page) {
Map<String, Object> initialSearchResult = performInitialSearch(query);
int totalResults = extractTotalResults(initialSearchResult);
int totalPages = calculateTotalPages(totalResults);
int adjustedPage = adjustPageNumber(page, totalPages);
int startIndex = calculateStartIndex(adjustedPage);
Map<String, Object> finalSearchResult = performPagedSearch(query, startIndex);
return createSearchResponse(finalSearchResult, adjustedPage, totalResults, totalPages);
}
private Map<String, Object> performInitialSearch(String query) {
String initialApiUrl = buildApiUrl(query, 1);
return executeApiCall(initialApiUrl);
}
private Map<String, Object> performPagedSearch(String query, int startIndex) {
String pagedApiUrl = buildApiUrl(query, startIndex);
return executeApiCall(pagedApiUrl);
}
private String buildApiUrl(String query, int startIndex) {
return String.format("%s?query=%s&display=%d&start=%d",
naverApiUrl, query, ITEMS_PER_PAGE, startIndex);
}
private Map<String, Object> executeApiCall(String apiUrl) {
HttpEntity<String> requestEntity = createRequestHeader();
ResponseEntity<Map> response = restTemplate.exchange(
apiUrl,
HttpMethod.GET,
requestEntity,
Map.class
);
return response.getBody();
}
private HttpEntity<String> createRequestHeader() {
HttpHeaders headers = new HttpHeaders();
headers.set("X-Naver-Client-Id", clientId);
headers.set("X-Naver-Client-Secret", clientSecret);
return new HttpEntity<>(headers);
}
private int extractTotalResults(Map<String, Object> searchResult) {
return (int) searchResult.getOrDefault("total", 0);
}
private int calculateTotalPages(int totalResults) {
return (int) Math.ceil((double) totalResults / ITEMS_PER_PAGE);
}
private int adjustPageNumber(int requestedPage, int totalPages) {
return Math.min(requestedPage, totalPages);
}
private int calculateStartIndex(int page) {
int startIndex = (page - 1) * ITEMS_PER_PAGE + 1;
return Math.min(startIndex, MAX_SEARCHABLE_ITEMS);
}
private Map<String, Object> createSearchResponse(
Map<String, Object> searchResult,
int currentPage,
int totalResults,
int totalPages) {
Map<String, Object> response = new HashMap<>();
response.put("items", searchResult.get("items"));
response.put("currentPage", currentPage);
response.put("total", totalResults);
response.put("itemsPerPage", ITEMS_PER_PAGE);
response.put("totalPages", totalPages);
return response;
}
}
1. 🔻 모든 로직을 searchProducts() → 역할 분리
이전에는 모든 로직을 searchProducts라는 하나의 함수 안에 몰아넣었지만, 이번에는 무의미한 Javadoc을 삭제했다.
또한 이름으로 의도를 드러내고, 주석도 API 형식과 규칙에 대한 정보만 남겼다.
/**
* 네이버 쇼핑 상품 검색 API
*
* @apiNote 네이버 API 정책상 최대 1000개 항목까지만 조회 가능
*/
@GetMapping
public ResponseEntity<BaseResponse<Map<String, Object>>> searchProducts(
@RequestParam String query,
@RequestParam(defaultValue = "1") int page) {
Map<String, Object> searchResult = executeNaverApiSearch(query, page);
return ResponseEntity.ok(new BaseResponse<>(BaseResponseStatus.SUCCESS, searchResult));
}적용된 원칙
- 작은 함수(Small Function): 하나의 함수는 하나의 일만 한다.
- 의도를 드러내는 이름(Meaningful Names): executeNaverApiSearch()가 뭘 하는지 이름만 봐도 감이 옴.
- 주석이 필요 없는 코드(Self-Documenting Code): 주석 없이도 로직의 의도가 드러남.
- 진짜 필요한 정보만 주석에 남기기: @apiNote는 API 제한처럼 꼭 필요한 정보만 남김
2. 🔻 HTTP 요청 헤더를 직접 설정 → createRequestHeader()로 추출
before
HttpHeaders headers = new HttpHeaders();
headers.set("X-Naver-Client-Id", clientId);
headers.set("X-Naver-Client-Secret", clientSecret);
HttpEntity<String> entity = new HttpEntity<>(headers);
after
private HttpEntity<String> createRequestHeader() { ... }적용된 원칙
- 중복 제거: 동일한 헤더 생성 로직을 재사용 가능하게 분리했다.
- 코드의 의도 명확히 표현: 이제, createRequestHeader()라는 이름 자체가 설명서 역할을 한다.
3. 🔻 긴 응답 처리 로직 → 각 역할별로 함수 분리
before
// 전체 검색 결과 수 확인
int totalResults = (int) body.getOrDefault("total", 0);
// totalResults 10으로 나누어 총 페이지 수 계산
int totalPages = (int) Math.ceil((double) totalResults / display);
// 페이지 번호가 총 페이지 수보다 크면 마지막 페이지로 조정
if (page > totalPages) {
page = totalPages;
}
// 페이지 번호에 맞게 시작 인덱스를 계산
int start = (page - 1) * display + 1;
if (start > 1000) { // start 값이 1000을 초과하지 않도록 제한 (API 자체 제한)
start = 1000;
}after
int totalResults = extractTotalResults(initialSearchResult);
int totalPages = calculateTotalPages(totalResults);
int adjustedPage = adjustPageNumber(page, totalPages);
int startIndex = calculateStartIndex(adjustedPage);적용된 원칙
- 코드를 읽는 사람이 더 적게 생각하게 하라 (Clean Code 철학이다!)
- 코드를 문장처럼 읽히게 하라: 전체 흐름이 마치 설명서처럼 자연스럽게 읽힌다.
4. 🔻 RestTemplate을 (매번) 새로 생성 → 생성자 주입으로 전환
before
RestTemplate restTemplate = new RestTemplate();after
@RequiredArgsConstructor
private final RestTemplate restTemplate;적용된 원칙
- DI(의존성 주입) 사용: 테스트 용이성, 코드 일관성 향상
- 불필요한 객체 생성을 피함: 메모리,성능 측면에서 이득
+) 💡의존성 꼬임방지! ReviewQueryService로 깔끔 분리

@Component
@RequiredArgsConstructor
public class ReviewValidator {
private final ReviewService reviewService; // ⚠️ 순환 참조 유발
...
}ReviewValidator는 리뷰 등록 전에 ReviewService의 hasActiveReview()를 호출하여, 사용자가 이미 주문상품에 리뷰를 작성했는지 검증한다. 반면 ReviewService는 검증을 위해 ReviewValidator를 호출한다.
즉, 다음과 같은 양방향 의존 관계가 생긴다:
- ReviewService → ReviewValidator
- ReviewValidator → ReviewService
여기서, "ReviewQueryService 없이도 ReviewValidator가 바로 DAO(Repository)를 쓰면 순환참조 없이 끝나는 거 아닌가?" 라는 의문이 들 수 있다.
하지만 나는 역할 분리의 원칙에 따라 ReviewValidator는 비즈니스 로직을 모르고 검증에만 집중하는 책임을 가지게 하고 싶었다.
ReviewValidator가 Repository에 직접 접근하면 검증 레이어가 DB 구조에 너무 많이 관여하게 되고, 추후 로직이 바뀌었을 때 그 영향을 받게 되기 때문이다.
(예를 들어 나중에 hasActiveReview() 로직이 변경되거나, 더 복잡한 조건이 붙었을 때, Validator에 직접 로직이 퍼지게 되는 것이다!)
이처럼 서로가 서로를 참조하는 구조는 스프링 컨테이너에서 순환 참조 에러를 유발하며, 유지보수 측면에서도 매우 좋지 않다!
적용한 구조: ReviewQueryService로 조회기능 분리
문제의 핵심은 ReviewValidator가 굳이 전체 ReviewService를 알 필요는 없다는 점이다.
그저 “이 사용자가 이 타임딜에 대해 리뷰를 이미 썼는지 여부”만 알면 되기 때문이다.
👉 그래서 이 조회 기능만 별도의 컴포넌트로 역할 분리하면, 순환 참조를 깨끗하게 끊을 수 있다.
ReviewQueryService 추가
@Service
@RequiredArgsConstructor
public class ReviewQueryService {
private final ReviewRepository reviewRepository;
public boolean hasActiveReview(Purchase purchase) {
return reviewRepository.existsByPurchaseAndDeletedAtIsNull(purchase);
}
}조회 전용 서비스로, 리뷰가 존재하는지만 판단한다. 트랜잭션도 @Transactional(readOnly = true)로 최적화할 수도 있다.
해결된 순환참조
ReviewService ⟷ ReviewValidator ← ❌ (순환 참조)
ReviewService → ReviewValidator → ReviewQueryService ← ✅ 단방향 구조
이에따라 의존 관계는 바뀐다. 예전에는 서로를 참조했다면,이제
- Validator는 검증만 담당
- Service는 비즈니스 로직만 담당
- QueryService는 데이터 조회만 담당한다.
각자의 역할이 명확해지고, 서로 얽히지 않아 구조가 훨씬 깔끔해졌다.
Validator는 "맞는지 아닌지만 판단"한다.
판단하기 위해 필요한 정보는 "QueryService"가 알아서 조회해준다.
이렇게하면, 검증 로직은 외부 구조(DB나 트랜잭션 등)에 의존하지 않고, 오직 규칙(도메인 룰)만 신경 쓸 수 있어진다!
또한 이는 함수 원칙에서 배웠던 아래 원칙을 따른다.
- 조회(Query) 메서드는 오직 데이터를 읽어와 반환만 한다.
- 명령(Command) 메서드는 오직 상태를 변경(부작용)만 수행한다.
'개발프로젝트' 카테고리의 다른 글
| [개발프로젝트] 스프링 API 예외 처리, 이제 try-catch는 그만! (1) | 2025.05.26 |
|---|---|
| [CleanCode] 형식 맞추기 – 형식 규칙에 대한 깊은 고찰,클린코드를 읽고... (1) | 2025.05.22 |
| [CleanCode] 함수 – 클린코드 원칙대로 리뷰 기능 함수를 리팩토링 해보자 (3) | 2025.05.19 |
| [개발프로젝트] 스프링 부트와 AWS로 혼자 구현하는 웹 서비스 chapter 10- 24시간 365일 중단 없는 서비스를 만들자 (1) | 2024.01.14 |
| [개발프로젝트] 스프링 부트와 AWS로 혼자 구현하는 웹 서비스 chapter 09- 코드가 푸시되면 자동으로 배포해 보자 (1) | 2024.01.11 |